Imagine that your company has developed a machine learning model to bring into a decision process. The idea is to make a business process run faster in an environment of rapidly increasing volumes of data and expectations for quick turnaround.
The model was tested and shown to perform better than human judgment. But because the decision it supports has real impact in human beings, we want to know more than the fact that the model makes fewer mistakes than a specialist. Our next goal is to enforce a notion of fairness so that the model accuracy doesn’t come at the expense of discrimination or bias that cause real harms to individuals belonging to a specific group.
Here, an extra step before approving a high-performance model is to assess to what extent the algorithm protects groups against harms of allocation (when we unjustly allocate or withhold certain groups an opportunity or resource).
The Disparity Evaluator is a tool that facilitates this assessment.
Example: Predicting whether a loan will be repaid
In this project, a classifier was designed to predict successful repayment of loans. The model output is 1 for success (repayment) and 0 for failure (default). The predictors (input variables) include characteristics of the loan applicants such as income, education level, employment history.
The model is intended to be used as the primary factor in the decision to grant a loan, and has been shown to be more accurate than human judgment (i.e., it makes fewer mistakes predicting the binary outcome of repayment or default). The business is not concerned with how many loans can be granted, only with:
- improving profitability by allowing the business to approve as many loans that will be repaid as possible while rejecting loans that will default;
- ensuring that no group based on race, age, or gender is penalized with a lower loan approval rate as a result of an incorrect prediction of default when in fact they will repay the loan..
Our goal is to assess whether the mistakes made by a binary classification model are consistent with the absence of bias or discrimination against specific groups. No machine learning model is entirely free from making mistakes, and we want reassurance that these mistakes are not unjustly impacting a group we wish to protect. In practice, this can happen for instance when a model is trained on a larger number of examples from one group. By definition, the rate of mistakes in the majority group counts more toward aggregate error than the error rate on the minority group. If the optimal model for accuracy was selected, it may come at the expense of more mistakes for members of minority groups.
Before bringing their models into production, the company wants to ensure it they are not creating disparate treatment based on certain characteristics (here we’ll focus on race, age, and gender, but it could be any other property that characterizes a group: wealth, nationality, disability status, sexual orientation, etc.).
Note that it doesn’t matter whether a characteristic is used as an input to the model for it to produce disparate treatment. Removing a property from the data won’t remove the algorithm’s ability to make decision based on that property because it can learn to deduce it from other input variables. (For more on this topic, check out Chapter 2 of The Ethical Algorithm: The Science of Socially Aware Algorithm Design by Michael Kearns and Aaron Roth.)
Using the Disparity Evaluator to test model bias
Note: The Disparity Evaluator is currently available as an open source Python library that can be installed and run locally. You can request the package free of charge via this contact form. A more user-friendly, online version is being produced to allow non-technical users to received an automated report without having to install the application locally.
For our problem, a metric of interest is False Negative Rate (FNR). This metric reflects the mistakes made by the model incorrectly predicting an applicant from a particular group will default the loan when they actually would repay.
The only inputs required for the Disparity Evaluator are:
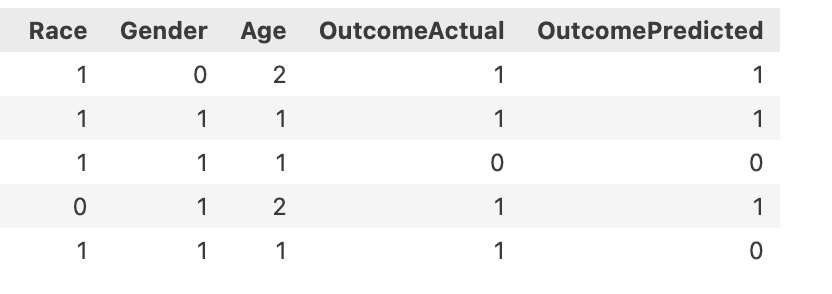
1) A CSV file with the variables of interest and the predicted and actual target variable (1 = repayment; 0 = default)
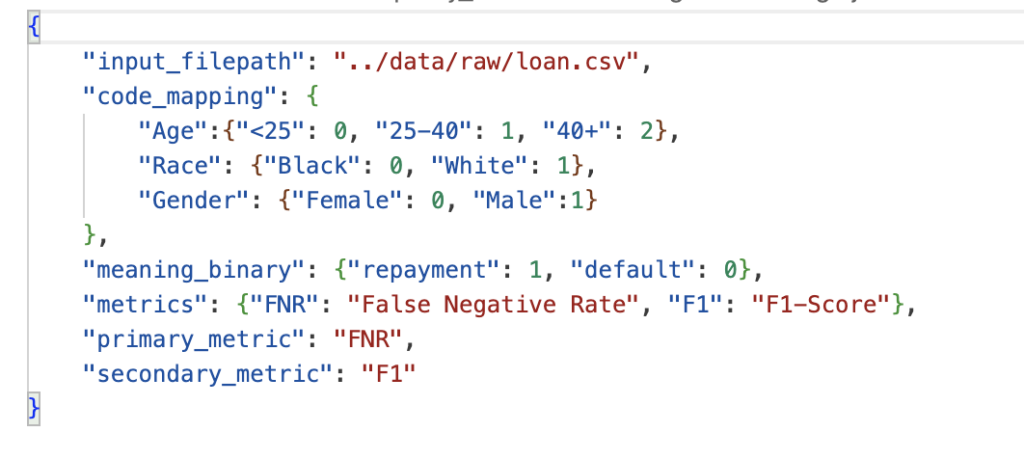
2) Some additional information provided to the tool by editing a default configuration file (location of the CSV file, mapping of codes used to represent predictors and outcomes, primary metric of interest (in our case, False Negative Rate):
Once these elements are provided, the tool generates charts and summary tables like the ones below.
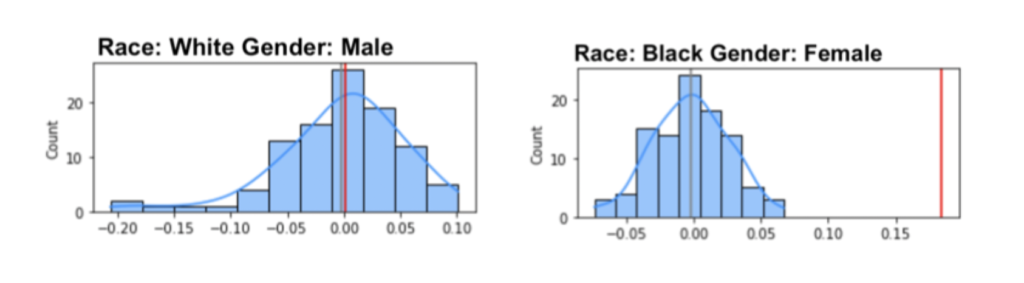
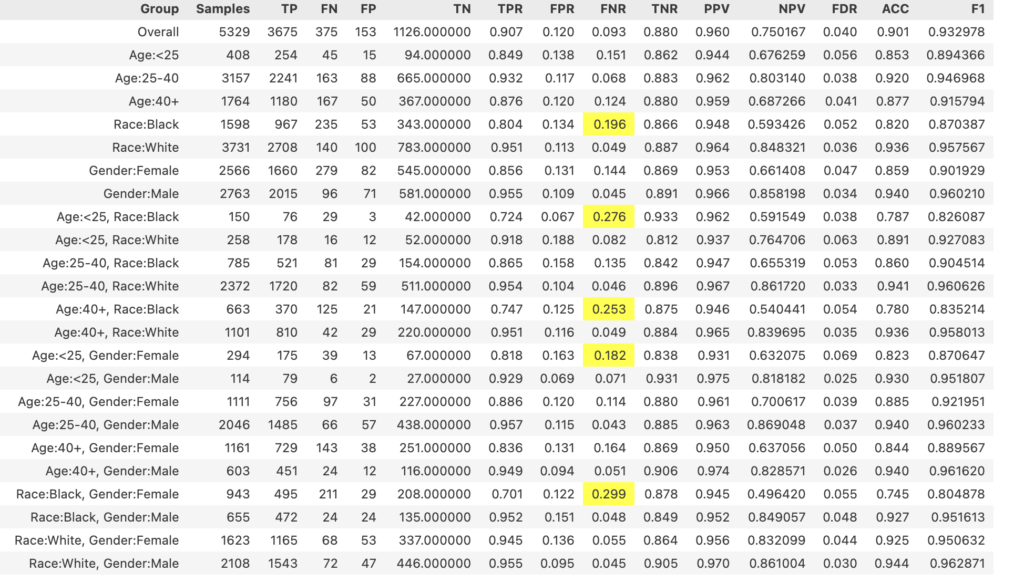
Based on the results above showing unfair treatment of certain minority groups, the next step would be to seek to improve the predictive model. Depending on the circumstances, one or more of the following strategies could be used:
- Improve the input to the model (for instance, adding more features or more examples of members of the affected minority groups).
- Ask the data science team to introduce a new goal on the learning process. Instead of optimizing only for error minimization, introduce a new rule so that the model minimizes for error subject to the constraint that it sticks to a particular notion of fairness among races, genders, and ages as much as possible.
- Attempt to use ensemble model (e.g. aggregate results from multiple models) to reduce error.
- Include extra steps in the process for members of the groups that is receiving unfair treatment (e.g., if a model is determined to make more mistakes assigning Black women to the “loan default” outcome when they will actually repay a loan, rather than rejecting applications from members of this group, they could be assigned to manual review).
- Reject the model in favor of a better alternative, such as continuing to use human judgment while working on a better model or better predictors to feed the existing one.
The Disparity Evaluator is currently available as an open source Python library. You can request the package for use free of charge via this contact form.